What It Takes to Fully Benefit from a Deployment Pipeline

To get the full power of a Deployment Pipeline, you need more than tools - you need practices that let it shine and reveal both your strengths and your weaknesses.

I spend most of my time maintaining our companies internal developer portal (IDP), known internally as Kazhoon (which is built on Backstage). Like any developer portal, it provides a lot of features built by a wide range of engineering teams.
Beyond my core team of maintainers, there are about 50 other contributors across the company who regularly develop their own plugins and features. All of these engineers push code to a single, giant monorepo.
As you can imagine, there are going to be a lot of challenges with this kind of setup. In this guide, I’m going to focus on solving one of them.
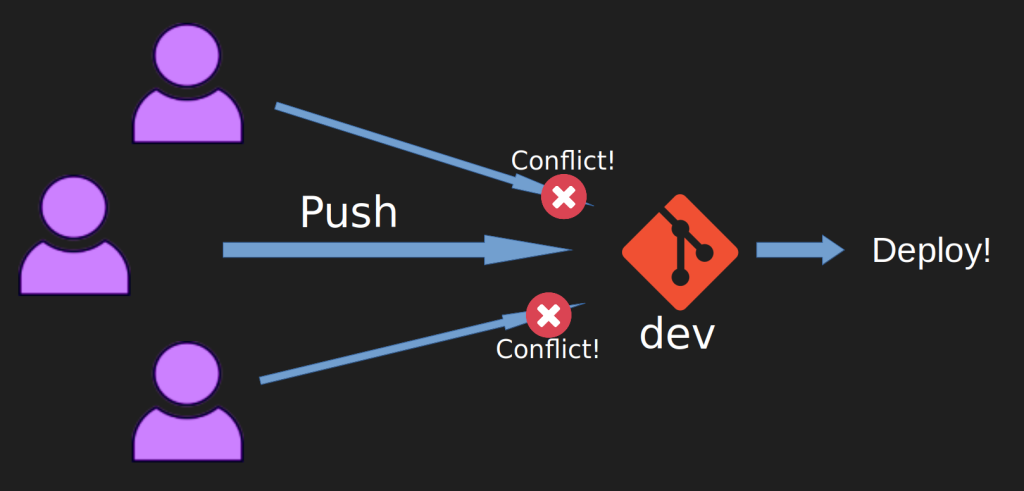
When contributors are working on some feature, before merging, they would like to test it out, usually in a staging/testing environment. A small team working on a project has no issues here. They will just internally coordinate who gets to deploy at what time. But when you have 5 teams simultaneously working on different features, you will get conflicts.
Our solution initially was to tell people to merge their “feature” branch into a “dev” branch that in theory should contain the features of all the other contributors as well. We would then deploy just this “dev” branch. In practice, however, we were still getting conflicts, just this time in a different place.
Contributors would have issues merging their changes into the dev branch due to several reasons. Sometimes the dev branch was outdated, missing the latest changes from the master branch. Sometimes the contributors branch was not up-to-date.
Sometimes someone doesn’t merge cleanly, which causes frustration to all the other people wanting to merge as well. Every few weeks we had to create a new “dev” branch from scratch because it just became impossible to fix the problems with the old one.
So how do we solve this problem? The answer came to me while experimenting with Kubernetes. I was in the process of migrating one of our projects from a traditional “Docker on a VM” setup into Kubernetes. The project in question, as you might guess, is Kazhoon, our internal developer portal (IDP).
Before explaining the solution, it helps to first understand how we deploy applications to Kubernetes.
Apart from having standard Kubernetes clusters, Infobip also leverages ArgoCD. A continuous delivery/deployment tool that sits between developers and Kubernetes. It uses GitOps principles to continuously sync infrastructure configuration stored in a Git repository with the actual cluster state.
This way, developers don’t need to directly interact with a Kubernetes cluster but instead just tweak and update the files in git and ArgoCD will make sure the changes get reflected in the actual Kubernetes cluster.
Also, it gives us a nice UI to monitor the changes.
So how do we deploy?
Well…, let’s say we want to deploy a “simple” application. In this case it is our IDP Kazhoon. Keep in mind that our app has do be dockerized for it to be deployed to Kubernetes.
P.S. The files below are created in a separate git repository that is linked with our ArgoCD application. For more information check out ArgoCD docs. Parts of the files have also been cut out for clarity.
We will first create a file which describes how our application should be deployed. Important parts have comments.
apiVersion: apps/v1 kind: Deployment # Type of resource in Kubernetes that manages our pods (aka. instances) metadata: name: backstage-deployment # Name of the resources namespace: infobip-kazhoon spec: replicas: 2 # Number of pods to create/manage selector: matchLabels: app: backstage-deployment template: # this is where we describe each deployment of our application metadata: labels: app: backstage-deployment spec: imagePullSecrets: - name: image-pull-secret containers: - name: backstage-deployment image: docker.domain.com/infobip-backstage:1.175.9 # dockerized image on internal artifact repository. imagePullPolicy: IfNotPresent # Yes, Kubernetes will cache your images, so if it already existed, it will reuse it based on the name/version. ports: - name: http # new port called "http" containerPort: 7007 # port where our application is listening envFrom: - configMapRef: name: backstage-config # Environment variables defined in a separate file - secretRef: name: backstage-secrets # 🕶️ Secret Environment variable defined in a separate file resources: # We don't need to provision VMs for our application, we just tell Kubernetes how "heavy" our app is and Kubernetes will make sure to give us enough power. requests: cpu: "1" memory: "1Gi" limits: cpu: "1" memory: "1Gi"
We also need some sort of internal load balancer for our pods to be able to connect to them. We need to create a Kubernetes Service.
apiVersion: v1 kind: Service # Type of Kubernetes resource that acts as an internal load balancer. It also allows other resources to communicate with out pods metadata: name: backstage-service namespace: infobip-kazhoon spec: selector: app: backstage-deployment # We tell the service which pods it should find ports: - name: http # we define a new port port: 80 # this port gets opened on the Service targetPort: http # resolves to the 7007 port of our pods (check the ports defined in the Deployment snippet)
As a last step we also want to allow for people outside the Kubernetes cluster to connect to our application. We need an Ingress
apiVersion: networking.k8s.io/v1 kind: Ingress # Type of Kubernetes resource that allows us to expose our internal network to the outside. In Infobip we use Haproxy for this. metadata: name: backstage-ingress namespace: infobip-kazhoon annotations: iks-external-dns.k8s.infobip.com/hostname: infobip-kazhoon-iot1.domain.com # special Infobip annotations that create a DNS record for our network cert-manager.io/common-name: infobip-kazhoon-iot1.domain.com # used for TLS cert-manager.io/cluster-issuer: vault-issuer # TLS spec: rules: - host: infobip-kazhoon-iot1.domain.com http: paths: - path: / pathType: Prefix backend: service: name: backstage-service port: number: 80 tls: - hosts: - infobip-kazhoon-iot1.domain.com secretName: minimal-ingress-cert # stores the certificate in this certificate resource
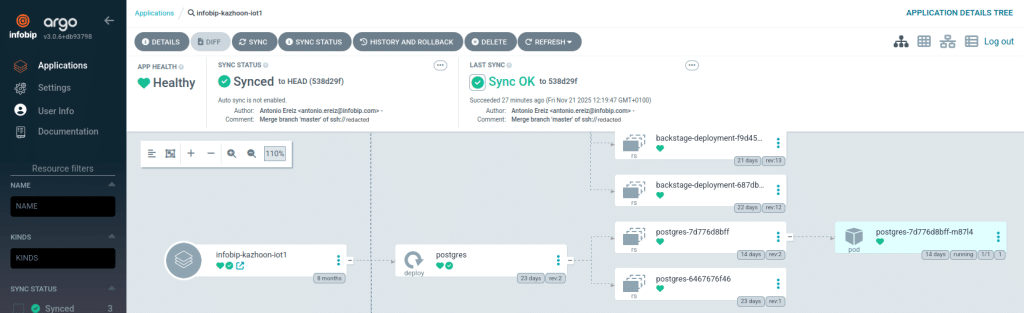
Once we create all the files, we push them to our git repository and hit “Sync” on ArgoCD. If we did everything okay we should see something like this:

Since this is a simplified “network” view we don’t see all resources (config files, certificates, etc…). The pods/instances on our right are the result of our “Deployment” resource which is not visible here.
As you can see, with just a handful of files we managed to completely skip VM provisioning as well as avoid the need to click through yet another UI just to deploy.
Kubernetes wasn’t just solving our infrastructure problems. Its design made it possible to solve the contributor problem I described at the beginning.
Instead of coordinating deployments, managing shared environments, or deciding who gets to test changes and when, we could let the platform do the work for us.
Everything could be automated.
Every change could have its own environment.
No coordination required.
The solution?
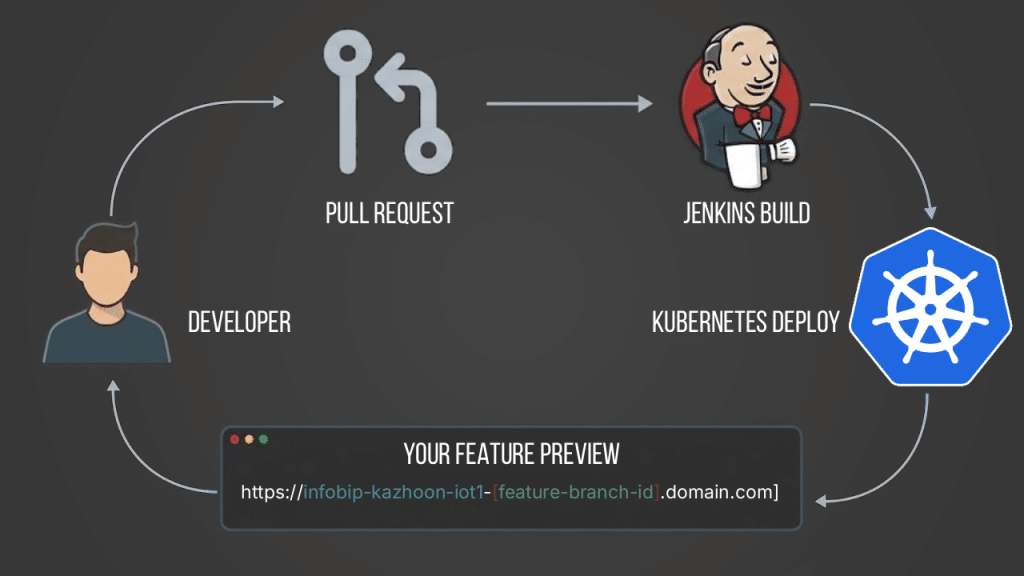
Whenever a contributor opens a new pull request, we can create an ephemeral (temporary) environment specifically for that branch, using the steps described in the example above.
We deploy the contributor’s branch to this environment and provide a unique link where they can test their changes.
This approach means contributors don’t need to think about deployment at all – everything happens automatically.
Each temporary environment is fully isolated from the others. The only shared component is the database, which could be further improved by switching to an in-memory solution.
Each environment has its own ingress, ensuring that every contributor receives a dedicated URL for their branch.
Because of this, we can eliminate the need for a separate dev branch and deploy feature branches directly.
Initially a contributor will just write some code, test it locally, and when happy, open up a pull request. This is where most developers would usually deploy to some IO environment that is close to a production setup for additional testing.
Instead of having to worry about the deployment, a Bitbucket webhook which listens to the PR_OPENED event will trigger a Jenkins job. The same Jenkins job that is used to build the main Kazhoon application. This is done to prevent duplication of jenkins groovy code as well as archetypes, which I will explain later. Simple hook below.
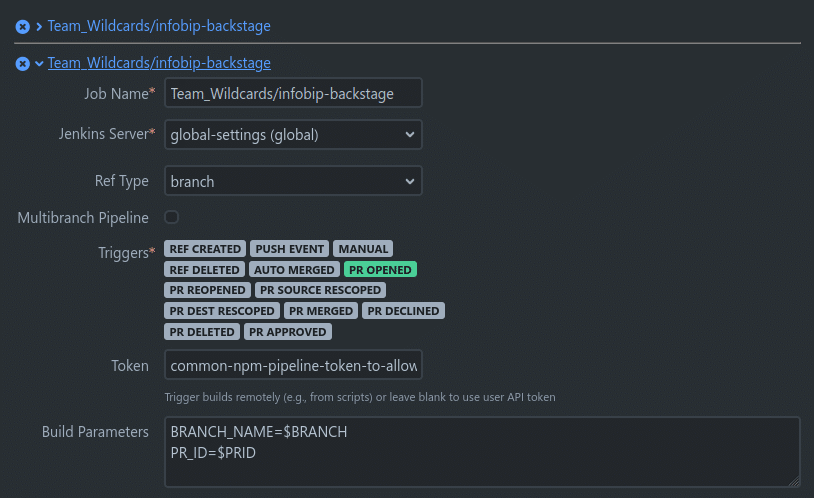
Notice the additional hook at the top. This is the main hook used for the app. It triggers the same Jenkins jobs but under different conditions (PUSH_EVENT – when code is pushed).
All of this can also be achieved on Github as well, using workflows.
Apart from the main logic for building Kazhoon and pushing a docker image (standard for most Infobip apps), we additionally need the setup for Kubernetes. Keep in mind that the Jenkins job runs every time new code gets pushed. We need a way to detect which code change is linked to a PR. In other words: Does the branch that is currently being built have an open PR linked to it?
Initially we figured we could just use the build parameter PR_ID as seen on the image above. This was working okay for testing, but then a problem appeared. How do we detect code changes? After all, we would like the most recent code to be deployed and not just the one that existed when we opened up the PR.
Sadly, the PR_ID parameter does not exist on regular code changes. We could create another hook using the PR_SOURCE_RESCOPED event, but that would mean that we will have duplicate Jenkins jobs. One for the newly added hook and one for the original “main” hook that always gets triggered when we push code. We need a different solution.
Luckily, it is possible to call APIs through Jenkins, so what we can do is call the Bitbucket API, check if the branch currently being built has an open pull request, and if so, initiate the Kubernetes setup. This logic can be done on the initial pull request open event as well as subsequent code change triggers. Here is how that would look like. Example written in a Jenkinsfile using scripted pipeline syntax.
def findPrForSourceBranch(sourceBranch) { withCredentials([string(credentialsId: globconst.GIT_HTTPS_TAG_TOKEN, variable: 'GIT_TOKEN')]) { def response = httpRequest( url: "${globconst.BITBUCKET_API_URL}projects/IAF/repos/infobip-backstage/pull-requests?state=OPEN&at=refs/heads/${sourceBranch}&direction=OUTGOING", httpMode: 'GET', contentType: 'APPLICATION_JSON', customHeaders: [[name: 'Authorization', value: "Bearer ${GIT_TOKEN}"]], validResponseCodes: '200' ) def prList = new groovy.json.JsonSlurper().parseText(response.content) if (prList.size > 0) { return prList.values[0].id } return null } } node('infobip-docker-nodejs:v20-dev') { LoadJenkinsPipelineLibrary(this) if (!env.PR_ID && env.BRANCH_NAME && env.BRANCH_NAME != 'master') { def prId = findPrForSourceBranch(env.BRANCH_NAME) if (prId) { env.PR_ID = prId echo "Found PR_ID=${prId} for branch ${env.BRANCH_NAME}" } else { echo "No PR found for branch ${env.BRANCH_NAME}" } }
In the later stages we can just check for the env.PR_ID. If it exists then there is a PR linked to the branch. Here is how that would look like:
def K8S_CONFIG_REPO = 'ssh://git-instance.com:7999/project-name/infobip-kazhoon.git' def K8S_CONFIG_BRANCH = 'master' def K8S_CONFIG_TARGET_DIR = 'k8s-config-repo' def featureName = env.BRANCH_NAME.toLowerCase().replaceAll(/[^a-z0-9_-]/, "-") ?: 'feature-preview' def k8sSafeName = env.BRANCH_NAME.toLowerCase().replaceAll(/[^a-z0-9-]/, "-").take(40).replaceAll(/-+$/, "") // Kubernetes name limit def dnsSafeName = k8sSafeName.take(24).replaceAll(/-+$/, "") // DNS name limit eg. infobip-kazhoon-iot1-feature-verylongbr.domain.com stage('Clone Kubernetes Config Repo') { // A neat trick to skip jenkins stages. Left out in later stages for brevity if (!env.PR_ID) { Utils.markStageSkippedForConditional(STAGE_NAME) return } // Clone the kubernetes repository where we put our initial files for deployment. sshagent(credentials: [GIT_CREDENTIALS]) { globlib.git.checkout(gitUrl: K8S_CONFIG_REPO, gitBranch: K8S_CONFIG_BRANCH, targetDir: K8S_CONFIG_TARGET_DIR) } } stage('Generate Kubernetes Files from Template') { def featurePath = "${K8S_CONFIG_TARGET_DIR}/feature/${featureName}" // Copy and customize template. The template looks similar to the 3 files we created for the deployment just with some parts containing placeholders instead of fixed values. sh """ mkdir -p ${featurePath} cp -r ${K8S_CONFIG_TARGET_DIR}/feature/template/* ${featurePath}/ # Replace placeholders in template for f in ${featurePath}/deployment.yaml ${featurePath}/service.yaml ${featurePath}/ingress.yaml; do sed -i -e "s|{{IMAGE_TAG}}|${dockerLabel}|" \ -e "s|{{K8S_SAFE_IMAGE_TAG}}|${k8sSafeName}|" \ -e "s|{{DNS_NAME}}|${dnsSafeName}|" \"\$f" done """ } stage('Push Kubernetes Resources to Git') { dir("${K8S_CONFIG_TARGET_DIR}") { sshagent(credentials: [GIT_CREDENTIALS]) { sh """ git config user.email "infobip-ci@infobip.com" git config user.name "Infobip CI (Jenkins)" git add . // We don't want the script to fail if there are no changes if ! git diff --cached --quiet; then git commit -m 'added feature ${featureName}' git push -u origin ${K8S_CONFIG_BRANCH} else echo 'No changes to commit' fi """ } } } stage('Trigger Sync on ArgoCD') { withCredentials([string(credentialsId: 'kazhoon_argocd_bearer_token', variable: 'BEARER_TOKEN')]) { def response = httpRequest( url: "https://argo-instance.com/api/v1/applications/infobip-kazhoon-iot1/sync", httpMode: 'POST', contentType: 'APPLICATION_JSON', customHeaders: [[name: 'Authorization', value: "Bearer ${BEARER_TOKEN}"]], validResponseCodes: '200' ) } // Utility function for posting comments to Bitbucket PR. postPrComment(env.PR_ID, "finish", """🚀 Your **feature environment** is live!  🌐 Access it here: [Preview URL](https://infobip-kazhoon-iot1-${dnsSafeName}.domain.com) ℹ️ Note that it might take a few minutes for the DNS to propagate and the service to become fully operational. ❗ If you encounter any issues, please contact [#kazhoon_contributors](https://infobip-support.slack.com/archives/C098ETXLL2U) on slack.""") }
After the PR is merged, the letfover deployment is automatically cleaned up using a separate webhook and Jenkins pipeline which I won’t go into detail for this blog post.
In short, when a PR is merged or deleted, a Jenkinsfile.cleanup pipeline is executed to remove all previously created resources and trigger a sync in Argo CD.
The same Jenkinsfile.cleanup pipeline also runs periodically to remove stale resources from old PRs, helping avoid unnecessary infrastructure and electricity usage.
Kubernetes and Argo CD allowed us to significantly improve the developer experience for everyone contributing to Kazhoon. By adopting a GitOps-driven approach, we eliminated the need to interact with a UI and, with it, the mental overhead of figuring out how and where to test changes. The entire deployment process is now fully abstracted away from contributors.
The original “dev” branch which was a major source of confusion and friction no longer exists. Developers work exclusively on their feature branches, each with its own isolated, production-like environment.
This setup also removed a large portion of our support overhead. Everything is automatic, predictable, and clearly communicated directly through pull request comments, allowing contributors to focus on what actually matters: building features.
Special shout-out to Matej Kern and his team for helping me throughout the entire process. From explaining Kubernetes concepts to setting up the infrastructure behind everything described in this post. This project would not have been possible without their support and guidance.
A huge shout-out as well to the maintainers and contributors behind these amazing projects and resources that made this workflow possible:
Hope you enjoyed this blog post. It’s my first official one (and definitely not the last). There’s a lot I didn’t manage to include, because it would’ve ended up being a whole novel, so if you have any questions or thoughts, I’m always happy to chat. Feel free to message me on X.

