
AI Won’t Replace Security Tools – It’s Helping Them Prioritize Biggest Threats

Mackenzie Jackson, security researcher and advocate, told me that AI can’t catch the bugs, but it knows which ones actually matter and provides the context teams need.

Right now, MCP is all the rage in AI-focused dev teams. Some folks even forgot that we had function calling for years, yet the market is rediscovering it all over again.
For the sake of understanding this piece, let’s just repeat that MCP is a standardized way of offering a list of different function calls to the LLM that reside on the MCP server.
We are still working with Language Models, and the possibility of having them execute functions is a godsent capability. Previously, we had to write the actual function every time we wanted to do a system integration – e.g. a travel agent calling a service to book you a flight, check the nearest accommodation, and so on.
So for example, for the Language Model to do math or know its time and place, you would write:
@function_tool
async def sqrt_number(x: int) -> float:
"""Returns the square root of a number."""
return x ** 0.5
@function_tool
async def what_is_the_time() -> str:
"""Returns the current time if the user asks for it."""
return f"The current time is {datetime.now().strftime('%H:%M:%S')}."
And then you’d give the LLM access to those functions.
The issue was that this wasn’t scalable – especially with today’s agentic approach, where your typical LLM app has to call multiple functions to reach external systems. Imagine us at Infobip having a few hundred of these for each API endpoint! It would quickly overwhelm the Language Model with possibilities.
Nowadays, you just put those on the MCP server and provide an endpoint. No need for dirty or repetitive implementations of the same API calls or low-level system functions.
Where’s the trick? It’s 2025, and now we do our tasks with multi-agents!
Everything discussed so far applies to agents too. A single agent doing a task is common, and your typical application logic might look like this:
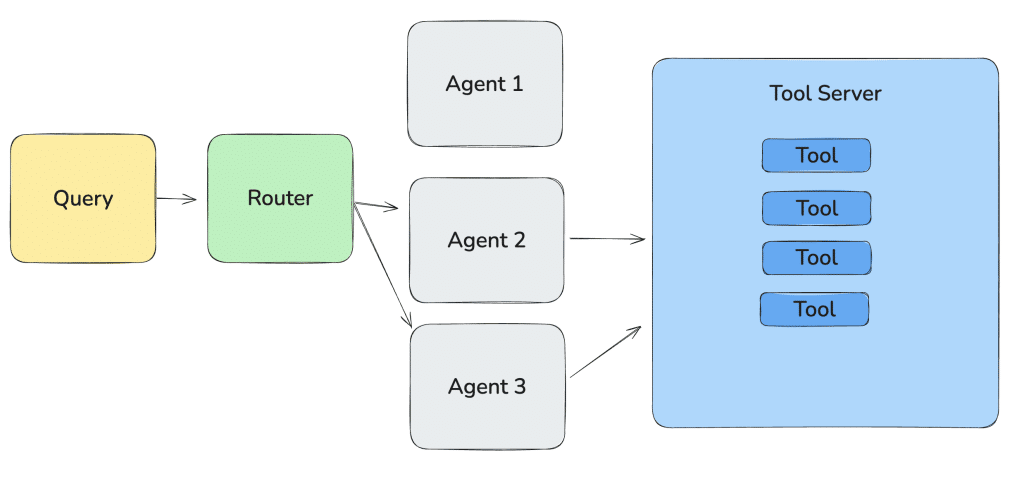
A router agent delegates tasks to two separate agents, each working in isolation. To make use of their results, you often need to gather all their outputs, combine them, and make an informed decision – or loop through the process until some condition is met. This usually means concatenating all context, maybe even preprocessing it, and then hoping for the best.
The problem? Each agent is flying solo, completely unaware of the broader context or the other agents in the system. This lack of shared understanding complicates the workflow, forcing developers to manually stitch everything together just to keep things accurate and coherent.
Sharing the context is somewhat doable within the same framework. So if you have agents ideally on the same server and using the same framework, you could achieve a common understanding between them. Route the request, concatenate the output – voila!
However, more often than not, you’ll have coworkers or clients building or integrating with something that’s not built using your framework of choice (LangGraph, CrewAI, AutoGen… you name it), and that makes things very messy.
Not to even mention weird routings and authentication between agents. Things get very complex, fast.
A2A simplifies this by exposing an agent in a standardized way.
Agent Card – Each agent must identify itself with some basic information: its name, purpose, availability (where it’s hosted), and how to communicate with it.

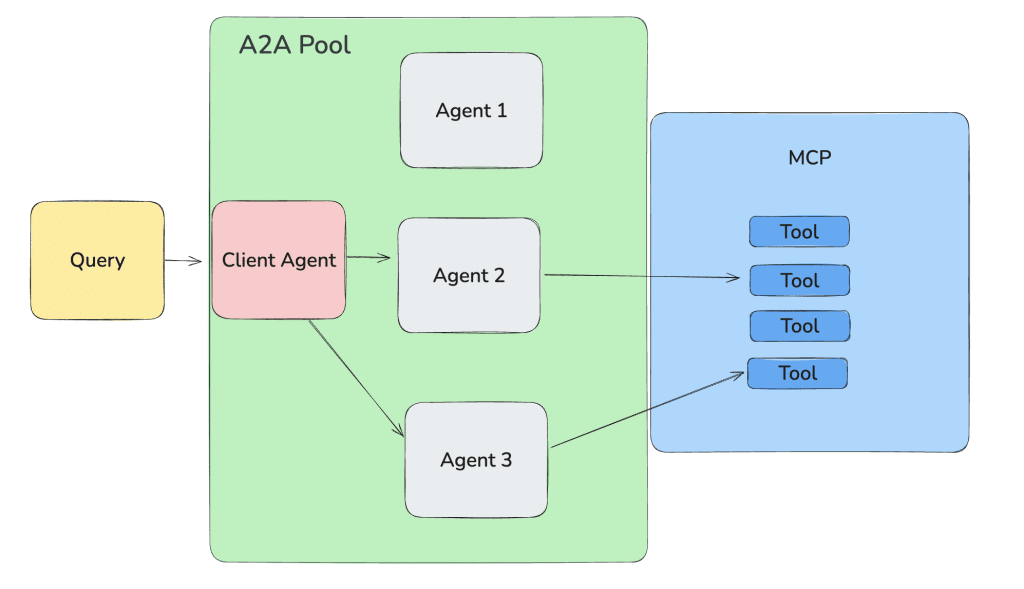
Tools live in their own bucket, agents in their own pool, and the whole setup abstracts away much of the underlying complexity.
By no means does this solve everything – both standards are still evolving rapidly – but it’s clear that:
Now that we have the full picture in front of us, we can say that what we’re really engineering here is context – the context between agents, and the tools that help keep that context relevant and accurate.
Prompt Engineering should probably be dead by now (but it isn’t). What’s happening instead is a shift: AI engineers are increasingly focused on the entire context, not just the system prompt.
That’s where the term context engineering comes in. Think of it as an expanded version of Prompt Engineering – one that includes all the juicy data flowing through the system: external data sources, tool calls, output formatting, and personalization (like memory).
This will always be the challenge (and writing a good prompt!). Having just one agent in the system go haywire could blow up the whole thing. The same is true for unsecured MCP endpoints – letting everyone (including your favorite prompt injection adversary) use your tooling in an unsafe way could potentially leak secrets.
There is another way forward. It’s much more conservative, still in the spirit of context engineering, but not going at it in an 8-lane highway style-rather, choosing the path more carefully. Personally, I’m a big fan of simple, yet effective and fast GenAI solutions that don’t try to do everything, but what they do -they do with the highest possible accuracy and business value.
This is exactly what was proposed in an interesting piece by Cognition, where the safety and accuracy of the response is preserved by not going too wide or too complex into the task.
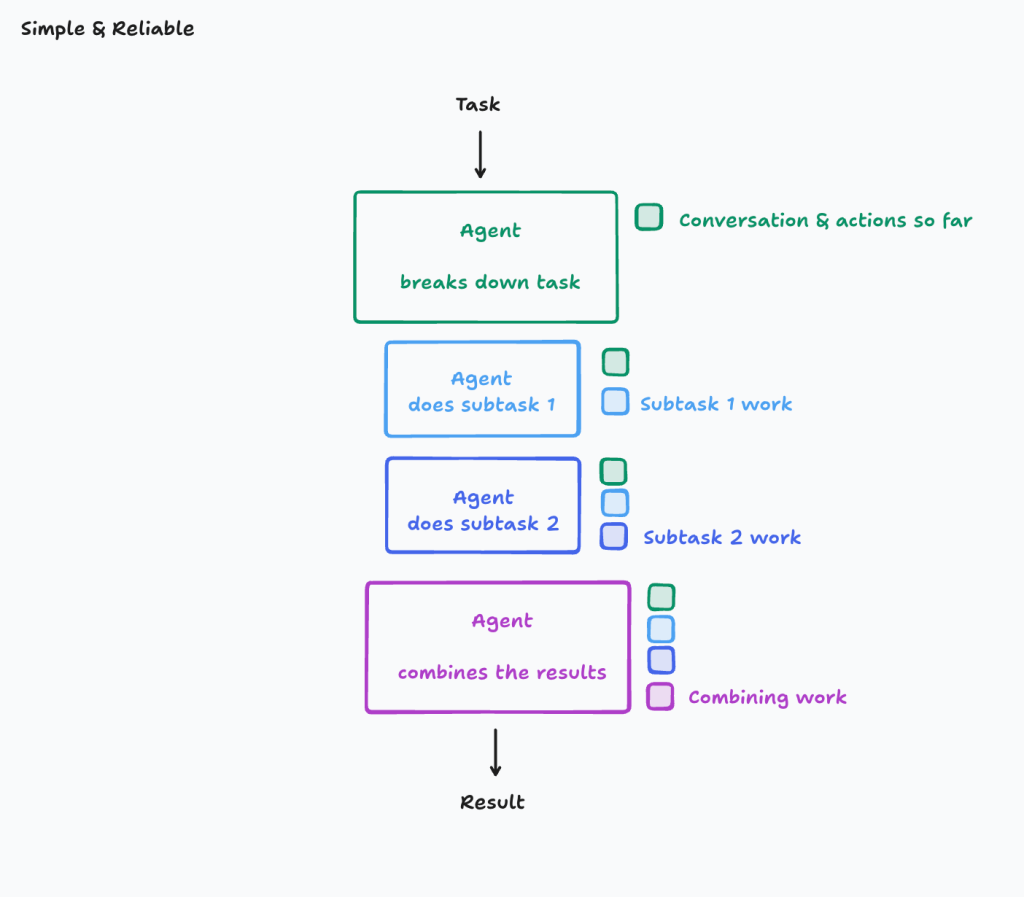
It’s still a multi-step approach, a (lang)chain, if you will – but it gets the job done in a more predictable, serialized fashion. Maybe we should strive to build simpler and more effective GenAI solutions.

